
Первая проблема, с которой мы начнём - это тушение пожара в инфраструктуре.
")
С какой стороны подойти к ней, будучи только что пришедшим в компанию руководителем? Для начала узнаем типы и виды горящих проблем, если, конечно же, они есть, параллельно изучая инфраструктуру, стэк, документацию. Данная информация поможет нам понять, как много слепых зон в документации в части инфраструктуры и понимания вектора масштабирования, если он необходим, что поможет в дальнейшем создать ряд распоряжений по их закрытию, где-то своими силами, где-то совместно с командой.
Далее посмотрим – планируются ли поставки оборудования. Если да, то какие и когда, если нет, то подсвечиваем это руководству, предварительно уточнив, есть ли в бюджетном планировании статья по инфраструктуре. Если, вдруг, такого нет, то проговариваем необходимость на ежегодной основе внедрения процесса бюджетирования инфраструктуры. Для этого описываем все критерии, которые нам скажут о том, что пора что-то расширить или купить, например, рост:
- потребностей бизнеса;
- количества пользователей приложения;
- количества компонентов приложения, которым нужны дополнительные ресурсы;
- переход на новые технологии, например, фреймворк разработки или с одной технологии кеширования на другую;
- появление новых технологий;
- и т.д
- в архитектуре CI/CD;
- в архитектуре тестовых или dev окружений;
- в инфраструктурном коде;
- пересмотр архитектуры БД или иных технических компонентов Вашей системы?
Собираем необходимую документацию, где необходимо, пишем бэклог по устранению проблем документации, белого шума алёртинга, покрытие белых пятен мониторинга, например, отсутствие Read/Write IO HDD кластеров k8s, и постепенно реализуем, не забывая делать осознанные изменения для того, чтобы минимизировать, насколько возможно, пожар.
Прежде чем мы перейдёт к описанию решения следующей проблемы, я дам ещё пару рекоммендаций. В качестве первой идеи - сделать общий dashboard по проблемам иинфраструктуры CI/CD в зондичном формате по всем элементам, вроде vmware фермы, hdd вашего наса и т.д., если, конечно же, этого ещё нет. Выглядеть это может вот так.

И вторая идея - реализация отдельного dashboard по просмотру состояния тестовых, персональны, дев и прочих контуров, которые могут не стабильно работать. За помощь воплощении идеи в жизнь реализацию отдельное спасибо супер бойцам - Алексею Зуеву и Алексею Пивоварову. Думаю, что они ещё напишут свои статьи по детальным разборам этих дашбордов, поэтому подробно тут останавливаться не будем.


Что входит в решение?
Прежде, чем перейдём к шагам, требуется уточнить, что эти шаги описаны в рамках стэка Atlassian с использованием инструмента реализации jira server. Для jira cloud, redmine, notion или прочих инструментов данный подход в том виде, что приводится ниже, не сработает из-за их ограничений или особенностей, этих инструментов, но, при наличие аналогичного функционала, это возможно будет реализовать.
Первым шагом мы создаём jira tempo teams, добавляем туда всех участников команды и начинаем контролировать время задач. До начала активностей в этом направлении будет не лишним провести мастер-класс или написать инструкцию для сотрудников подразделения, если они не в курсе, что это такое и никогда с этим не работали.

Далее мы создаем необходимые фильтры и jira dashboard, построенный на основе них. Что сюда можно добавить?
- круговую диаграмму распределения количества задач на каждом участнике подразделения;

- вывод ряда фильтров по нераспределённым задачам, назначенным на тех уз, задачи-«потеряшки», блокеры и т.д.;

- табель учёта времени команды для наблюдения за тем, кто и на что тратит время в течение недели до отправки timesheets на approve. В части фильтра нераспределённых задач посоветую хороший паттерн. Создание задач jira на подразделение удобно тем, что можно автоматически заполнять ряд полей, а также отслеживать весь входящий трафик задач;

- статистику по фильтру, кто, сколько и каких типов задач за период закрывал;

- общее количество тасков на период (напр., квартал) с разбиением на epic theme;

- статистика открытых задач с указанием времени сколько в каком статусе провела каждая задача;

-
и другие.
Затем создаем сущность в виде Epic theme (Epic link), Sales, Story или Account, в зависимости от того как у Вас в компании принято вести крупные активности. В нашем случае epic theme равно типам работ, которые осуществляет служба, выше на скрине они описаны.
Выглядеть это может так:

Реализуем создание kanban доски на основе ранее созданных фильтров. Кто-то разбивает доски по проектам или активностям, где одна доска = один проект. Я же решил всё положить в одном месте с разбивкой на сотрудников горизонтально, а вертикально по фильтрам разбил на доске виды активностей, получилось как-то так.

Ставим на рельсы ежедневные митинги, на которых обсуждаем распределение задач, их статусы, планы на день, у кого какие проблемы и нужна помощь и т.д. То есть проводим летучки, или daily meeting, кому как удобно. При этом я обычно делаю всегда встречи по понедельникам чуть длиннее, чтобы, помимо текучки, обсудить крупные задачи, которые запланированы именно на эту неделю.
Но нужно понимать не только команду в целом, но и состояние каждого сотрудника, поэтому мы организуем TED/тет-а-тет/обратная связь/one to one встречи с каждым сотрудником подразделения раз в 2-3 недели.

Вводим тип задач DevOps c облегчённым flow для взаимодействия со всеми участниками цикла разработки для лучшего контроля активностей подразделения. То есть перестаём работать в других типах задач, и, в некоторых случаях, полностью отказываемся от работы в sub-task.
Так же, на мой взгляд, проще завести сущность jira epic link или epic theme и создавать задачи в рамках них, но это вкусовщина и больше предмет для холивара, т.к. кто-то любит jira account, кто-то sales или product сущности. В некоторых случаях, полезным будет в тип задачи добавлять дополнительные поля, на основе которых можно собирать дополнительные метрики или статистику по задачам, которые проходят через подразделение DevOps, например, тип работ или бизнес-эффект от задачи, но это на вкус и цвет. Данные поля могут помочь закрыть слепые зоны активности подразделения в части коммуникации с другими подразделениями. И тут так же может помочь дополнительное поле, например, TeamLead, в котором будет указан руководитель сотрудника, что, порой является не лишней информацией при эскалации необходимости эскалации, или уточнении, почему задача долго не берётся в работу.

Какой может быть Flow? Я рекомендую его в начале максимально упрощать, расширить его можно будет позднее. Пример такого Flow Вы можете увидеть на скриншоте ниже.

Дополнительно для контроля рекомендую ввести аллокацию FTE (full-time employee). В качестве резерва рекомендую закладывать 20 % общего рабочего времени «на пожары». Это означает, что подразделение обеспечено плановыми задачами на 80% своей загрузки, а 20% остается на форс-мажоры и устранение пожара. В редких случаях этот процент может быть увеличен, если случилось что-то совсем критичное, вроде падения инфраструктуры, или метеорит прилетел в ЦОД. Поэтому, как показывает практика и личный опыт, 20% - это адекватная и реалистичная цифра.

Теперь мы можем планировать эту аллокацию на любой интервал времени: квартал, спринт, релиз и т.д. На скриншоте можно увидеть, как мы, используя аллокацию запланировали ресурсы нашего подразделения на третий квартал по типам работ.
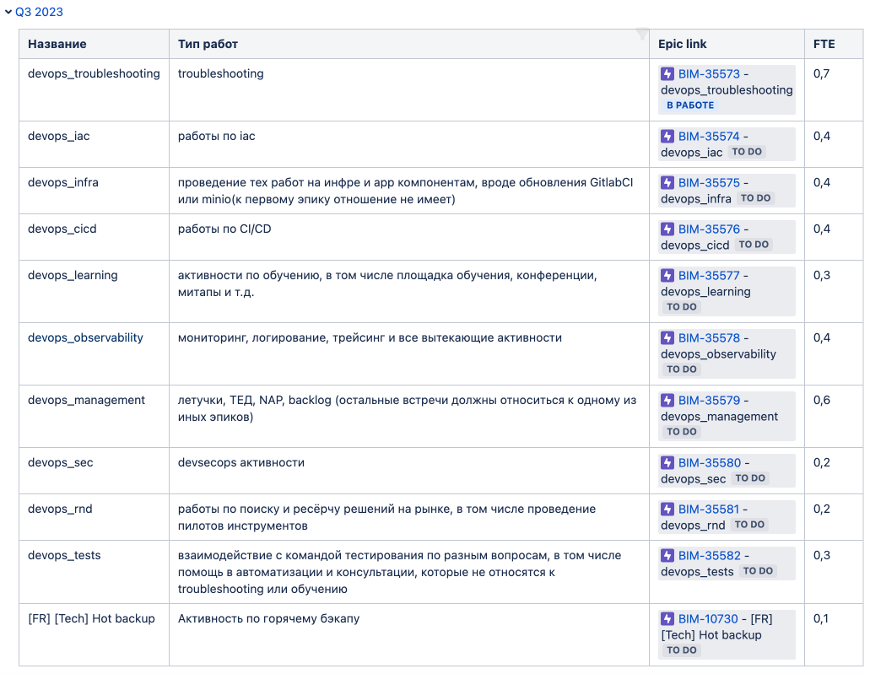
Наблюдаем, строим отчёты, и смотрим, где есть какие-то просадки по активностям, проблемы и устраняем их теми или иными решениями.
Ещё один совет, да я люблю давать их много – планируем teambuilding команды. Учитывая реалии нашей жизни, это не маловажно, поэтому, когда есть возможность дополнительно сплотить команду, не стоит от нее отказываться.

Может возникнуть вопрос: "Зачем нам необходим контроль за подразделением?”

Вот, что он нам дает:
-
контроль команды;
-
прозрачность работ и ресурсов;
-
виден пул всех задач в одном месте;
-
понимание аллокаций на сейчас и на будущее;
-
понимание вариантов развития бойцов;
-
понимание времени решения проблем на основе трека в задачи.
Что ещё дополнительно может стать нам подспорьем, в том числе по работе с инфраструктурой?
Пусть это будет дополнительная автоматизация по концепту ChatOps.
Автоматизация создания задач по проблемам build/deploy.

Например, нотификация системы CI/CD по build/deploy failed, в нашем случае GitlabCI, плюс генерация задачи в jira с последующей нотификаций, например в MS Teams или в Slack, Telegram.
Кстати, тут есть пример реализации такого скрипта для геннерации таски в jira - https://github.com/darkbenladan/create_jira_task
Следующий вариант автоматизации - Автоматизация по PR из GitLab в чаты.

К нам часто приходят с подобными запросами, поэтому мы решили это автоматизировать. Теперь если к нам приходят PR, мы сразу его видим в виде нотификации в конкретный чатик.
Ещё одна полезная фича - это возможность создания задач jira из чата.

Что тут можно добавить. Есть одна очень неприятная штука, например, при интеграции jira server c slack. Проблема в том, что часть функционала плагина jira server не функционирует, работает только нотификация, а создание и манипуляция с тасками, нет. Теперь данный функционал доступен только для версии jira cloud. Другой пример, случай с MS Teams, есть много бесплатных плагинчиков, которые могут помочь вам работать с jira, от создания тасок, комментирования, до подписки на задачу. Это достаточно удобная интеграция, благодаря которой Вы можете перевести процесс заведения тикетов напрямую из чата. Таким образом Вы решаете проблему сбора статистики из чатов на предмет количества обращений по консультациям или проблемам. Путём таких нехитрых манипуляций, мы закрываем проблему отсутствия контроля за активностью подразделения.
Ряд озвученных в предыдущей стать проблем, мы решили. В последующих статьях мы рассмотрим решение:
-
Хаотичное ведение задач через чат;
-
Порядка 60% активности подразделения DevOps поступает через мессенджеры;
-
Нет понимания развития сотрудников, отсутствие ИПР;
-
Отсутствие процесса внедрения и фильтрации технологий (разработка, инфраструктура, CI/CD);
-
Нет процесса работы с бэклогом и сквозной приоритизации;
-
Смещение фокуса с развития на поддержку.
Но а с Вами был Крылов Александр, до новых встреч в следующих статьях.